
AI·빅데이터 융합 경영학 Study Note
[ML수업] 10주차 실습1: pipeline_basics 본문
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import SelectPercentile
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.decomposition import PCA# load and split the data
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0)### Building Pipelines
The **Pipeline** is built using a list of **(key, value)** pairs, where the **key** is a string containing the name you want to give this step and **value** is an estimator object:
# Build Pipelines
from sklearn.pipeline import Pipeline
#반드시 튜플 형태로 입력해야 함.
pipe = Pipeline([('scaler', MinMaxScaler()), ('selector', SelectPercentile()), ("svm", SVC())])You only have to call **fit** and **predict** once on your data to fit a whole sequence of estimators'
pipe.fit(X_train, y_train).score(X_test, y_test)
#0.9440559440559441
### Using Pipelines in Grid-searches
Parameters of the estimators in the pipeline shoud be defined using the **estimator__parameter** syntax
param_grid = {
'selector__percentile': range(10, 100, 10),
'svm__C': [0.001, 0.01, 0.1, 1, 10, 100],
'svm__gamma': [0.001, 0.01, 0.1, 1, 10, 100]
}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best cross-validation accuracy: {:.2f}".format(
grid.best_score_))
print("Test set score: {:.2f}".format(grid.score(X_test, y_test)))
print("Best parameters: {}".format(grid.best_params_))
print(grid.score(X_test, y_test))
"""
grid = GridSearchCV(pipe, param_grid=param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best cross-validation accuracy: {:.2f}".format(
grid.best_score_))
print("Test set score: {:.2f}".format(grid.score(X_test, y_test)))
print("Best parameters: {}".format(grid.best_params_))
print(grid.score(X_test, y_test))
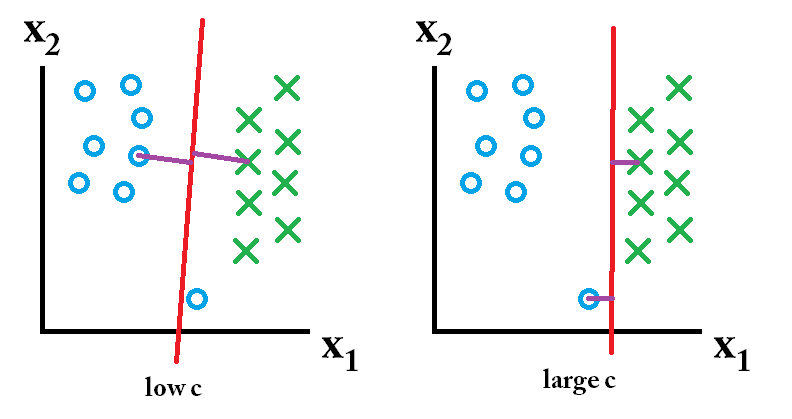
"""C parameter: hard margin vs. soft margin
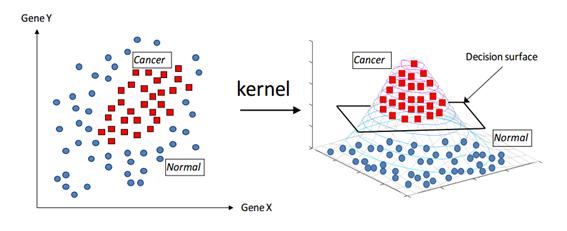
Kernel Trick
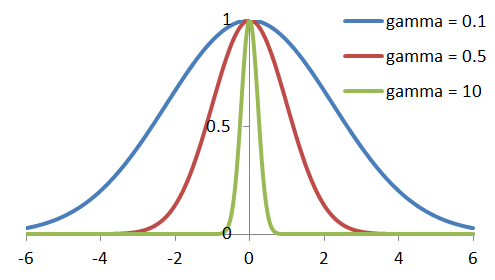
Gamma parameter

Convenient Pipeline creation with *make_pipeline*
from sklearn.pipeline import make_pipeline
# standard syntax
pipe_long = Pipeline([("scaler", MinMaxScaler()),
('selector', SelectPercentile(percentile=70)),
("svm", SVC(C=100,gamma=0.01))])
# abbreviated syntax
pipe_short = make_pipeline(MinMaxScaler(), SelectPercentile(percentile=70), SVC(C=100,gamma=0.01))
print("Pipeline steps:\n{}".format(pipe_short.steps))
"""
0.9440559440559441
Best cross-validation accuracy: 0.98
Test set score: 0.98
Best parameters: {'selector__percentile': 70, 'svm__C': 100, 'svm__gamma': 0.01}
0.9790209790209791
Pipeline steps:
[('minmaxscaler', MinMaxScaler()), ('selectpercentile', SelectPercentile(percentile=70)), ('svc', SVC(C=100, gamma=0.01))]
"""
#추가로??
pipe = make_pipeline(StandardScaler(), PCA(n_components=2),
StandardScaler())
print("Pipeline steps:\n{}".format(pipe.steps))'AI·ML' 카테고리의 다른 글
| [ML수업] 10주차 실습4: pipeline_stacking 예시 코드1 (0) | 2023.11.21 |
|---|---|
| [ML수업] 10주차 실습2: Hyperparameter Tuning using Pipeline+Optuna 예시 코드 (0) | 2023.11.21 |
| [ML수업] 8주차 실습6: feature engineering- Feature Generation (0) | 2023.11.21 |
| [ML수업] 8주차 실습5: feature engineering- Dimensionality Reduction (차원 축소) (0) | 2023.11.21 |
| [ML수업] 8주차 실습4: feature engineering- Feature Selection (0) | 2023.11.21 |
'AI·ML' Related Articles
more



