
목록분류 전체보기 (154)
AI·빅데이터 융합 경영학 Study Note
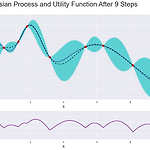 [ML수업] 5주차 실습2: model tuning(hyperparameter optimization), grid search CV, randim search CV, Baysian optimization with optuna
[ML수업] 5주차 실습2: model tuning(hyperparameter optimization), grid search CV, randim search CV, Baysian optimization with optuna
from sklearn.datasets import load_digits digits = load_digits() #import optuna from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, random_state=0) from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.svm im..
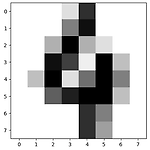 [ML수업] 5주차 실습1: Cross-Validation(LOOCV(Leave-One-Out), Shuffle-Split)
[ML수업] 5주차 실습1: Cross-Validation(LOOCV(Leave-One-Out), Shuffle-Split)
Cross-Validation # 사이킷런에서 제공하는 손으로 쓴 숫자(0~9) 이미지 데이터 세트 (8x8 픽셀) from sklearn.datasets import load_digits digits = load_digits() # 'data', 'target', 'target_names', 'images', 'DESCR' 필드로 구성 digits.keys() # dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR']) # digits.data는 이미지 속성을, digits.target는 클래스 레이블(0~9)을 갖고 있음 import matplotlib.pyplot as plt %matplotli..
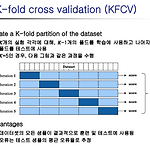 [ML수업] 4주차 이론: cross validation (교차검증)
[ML수업] 4주차 이론: cross validation (교차검증)
1. K-fold cross validation(KFCV)2. Stractified KFCV3. Hyperparameter Optimization ◼ Hyperparameter Optimization학습을 수행하기 위해 사전에 설정해야 하는 값인 hyperparameter의 최적값을 탐색하는 문 제. 여기서, 최적값이란 학습이 완료된 러닝 모델의 일반화 성능을 최고 수준으로 발휘하도 록 하는 hyperparameter 값을 의미◼ Manual Search◼ Grid Search탐색의 대상이 되는 특정 구간 내의 후보 hyperparameter 값들을 일정한 간격(grid)을 두고 선정하여, 이들 각각에 대하여 성능 결과를 측정한 후 가장 높은 성능을 발휘했던 hyperparameter 값을 최적값으로 선..
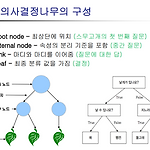 [ML수업] 3주차 이론2: decision tree (의사결정나무)
[ML수업] 3주차 이론2: decision tree (의사결정나무)
1. 의사결정나무(Decision Tree) 개요◼ 분류와 예측에서 자주 사용되는 강력하고 인기 있는 도구◼ 분류 결과를 인간이 쉽게 이해할 수 있는 규칙으로 표현 - 대출 상담자에게 대출을 해 줄 경우, 정확한 근거를 제시하여 대출을 거부할 자료를 제시할 수 있음 - If 연간 수입 $20,000이상 and 관련 계좌가 3개 이상 then 대출◼ 다수의 feature와 class 간의 관계에 대한 통찰을 얻을 수 있기 때 문에 데이터 탐색 과정에서도 널리 활용◼ 주요 의사결정나무 알고리즘 - Categorical class만 가능: C5.0, QUEST - Numeric & categorical class 모두 가능: CART, CHAID* scikit-learn의 ..
 [ML수업] 3주차 이론1: overfitting and regularization (과적합과 정규화)
[ML수업] 3주차 이론1: overfitting and regularization (과적합과 정규화)
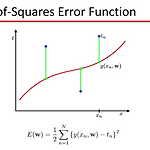
Sum of Suares Error function RMS RMS는 다음과 같은 단계를 거쳐 계산됩니다:제곱: 각 데이터 포인트 또는 신호의 값을 제곱합니다. 이는 모든 값을 양수로 만들어서 평균을 계산할 때 음수 값이 상쇄되지 않도록 합니다.평균: 제곱한 값들의 평균을 구합니다.제곱근: 평균 값을 다시 제곱근으로 변환합니다.수식으로 표현하면 다음과 같습니다: RMS 값이 높은 경우, 해당 신호나 데이터가 평균적으로 큰 값을 가지며 변동이 심하다는 것을 의미합니다. 반대로, RMS 값이 낮으면 신호나 데이터가 평균적으로 작고 변동이 적다는 것을 의미합니다. RMSE 축 설명:X축 (M): 모델의 복잡성을 나타냅니다. 이 경우, 모델의 차수(다항식 차수 또는 매개변수 수)로 이해할 수 있습니다. ..
오류 문구: No module named 'kerastuner' 해결방법 !pip install keras-tuner --upgrade 해결됨.
 [파이썬] 열의 값 목록 전체 출력
[파이썬] 열의 값 목록 전체 출력
난 그저... 엑셀에 필터 열면 나오는 특정 열의 값 목록을 별도의 파일로 추출하고 싶었다. X_train['대학전공'].value_counts() ... 실패 list_of_single_column = list(X_train["대학전공"]) list_of_single_column.sort() for i in list_of_single_column: print(i) 실패 list_of_single_column = list(X_train["대학전공"]) list_of_single_column.sort() i = 0 while i < len(list_of_single_column): print(list_of_single_column[i]) i += 1 또 실패 그렇게 마침내 찾은 방법 에서 "scrollab..
지정된 열의 각 값(value)에 대한 모든 발생 횟수를 반환하는 df['열'].value_counts() 의 기본적인 사용법은 아래 링크 참고 https://zzinnam.tistory.com/entry/pandas-valuecounts-%ED%95%A8%EC%88%98 pandas value_counts() 함수 Pandas의 value_counts() 함수는 데이터분석을 하는데 있어, 가장 기초적이면서 일반적으로 사용되는 함수 중 하나입니다. 기본적으로 지정된 열의 각 값(value)에 대한 모든 발생 횟수를 반환합니다. zzinnam.tistory.com
https://answers.microsoft.com/ko-kr/windows/forum/all/%EC%9C%88%EB%8F%84%EC%9A%B0-10/d4cfa3df-0558-41d0-9af2-ef43288ceac2 리디렉션 중 login.microsoftonline.com 요약 일본어 타자 -> 영어 타자 : 윈도우 + space 영어 타자 -> 일본어 타자 : ???
https://pandas.pydata.org/pandas-docs/stable/user_guide/options.html#available-options Options and settings — pandas 2.1.3 documentation Warning Enabling this option will affect the performance for printing of DataFrame and Series (about 2 times slower). Use only when it is actually required. Some East Asian countries use Unicode characters whose width corresponds to two Latin characters. I pand..
 [파이썬] csv 파일이 깨져요 ㅠㅠ
[파이썬] csv 파일이 깨져요 ㅠㅠ
https://mainia.tistory.com/6658 엑셀 Excel CSV 파일 한글 깨짐 해결하기, ANSI 를 UTF-8 로 변환하기 CSV 파일은 문자 인코딩 문제로 인해 한글이 깨질 수 있으며, 이로 인해 데이터 오류와 혼란이 발생할 수 있습니다. 한글 텍스트를 올바르게 표시하고 데이터를 정확하게 분석하기 위해서는 반드 mainia.tistory.com ▼ CSV 파일을 엑셀로 오픈했는데, 아래와 같이 한글이 깨져 보인다면 텍스트 인코딩 문제입니다. ▼ 인코딩 변환은 윈도우 텍스트 프로그램인 메모장(notepad) 를 이용할 것입니다. CSV 파일을 선택하고 오른쪽 마우스를 눌러 연결 프로그램 > 메모장을 클릭합니다. ※ 아래는 참고하면 좋을 만한 글들의 링크를 모아둔 것입니다. ※ ▶ 엑셀..
https://www.snugarchive.com/blog/python-pandas-guide-3/ Python pandas 데이터 병합, 정제, 변형하는 법 데이터 준비 3단계 www.snugarchive.com X_train = pd.read_csv('X_train.csv', encoding='cp949').copy() y_train = pd.read_csv('y_train.csv', encoding='cp949').copy() # merge files df=pd.merge(y_train, X_train, on='ID') df.to_csv("X_train,y_train병합.csv", index = False)