
목록AI·ML (31)
AI·빅데이터 융합 경영학 Study Note
 [ML수업] 6주차 이론: measuring model performance(모형평가)
[ML수업] 6주차 이론: measuring model performance(모형평가)
1. 모형 평가 ◼ 모형평가란- 고려된 서로 다른 모형들 중 어느 것이 가장 우수한 예측력을 보유하고 있는 지, 선택된 모형이 '임의의 모형(random model)' 보다 우수한지 등을 비교 하고 분석하는 과정을 말한다.- 이 때 다양한 평가지표와 도식을 활용하는데, 머신러닝 애플리케이션의 목적이나 데이터 특성에 따라 적절한 성능지표(performance measure)를 선 택해야 한다.◼ 모형 선택 시 고려사항- (일반화 가능성) 같은 모집단 내의 다른 데이터에 적용하는 경우 얼마나 안 정적인 결과를 제공해 주는가?- (효율성) 얼마나 적은 feature를 사용하여 모형을 구축했는가?- (정확성) 모형이 실제 문제에 적용될 수 있을 만큼 충분한 성능이 나오는가? 2. 주요 평가 지표 3. Confu..
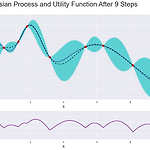 [ML수업] 5주차 실습2: model tuning(hyperparameter optimization), grid search CV, randim search CV, Baysian optimization with optuna
[ML수업] 5주차 실습2: model tuning(hyperparameter optimization), grid search CV, randim search CV, Baysian optimization with optuna
from sklearn.datasets import load_digits digits = load_digits() #import optuna from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, random_state=0) from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.svm im..
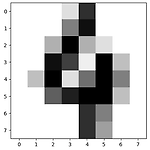 [ML수업] 5주차 실습1: Cross-Validation(LOOCV(Leave-One-Out), Shuffle-Split)
[ML수업] 5주차 실습1: Cross-Validation(LOOCV(Leave-One-Out), Shuffle-Split)
Cross-Validation # 사이킷런에서 제공하는 손으로 쓴 숫자(0~9) 이미지 데이터 세트 (8x8 픽셀) from sklearn.datasets import load_digits digits = load_digits() # 'data', 'target', 'target_names', 'images', 'DESCR' 필드로 구성 digits.keys() # dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR']) # digits.data는 이미지 속성을, digits.target는 클래스 레이블(0~9)을 갖고 있음 import matplotlib.pyplot as plt %matplotli..
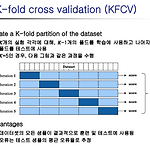 [ML수업] 4주차 이론: cross validation (교차검증)
[ML수업] 4주차 이론: cross validation (교차검증)
1. K-fold cross validation(KFCV)2. Stractified KFCV3. Hyperparameter Optimization ◼ Hyperparameter Optimization학습을 수행하기 위해 사전에 설정해야 하는 값인 hyperparameter의 최적값을 탐색하는 문 제. 여기서, 최적값이란 학습이 완료된 러닝 모델의 일반화 성능을 최고 수준으로 발휘하도 록 하는 hyperparameter 값을 의미◼ Manual Search◼ Grid Search탐색의 대상이 되는 특정 구간 내의 후보 hyperparameter 값들을 일정한 간격(grid)을 두고 선정하여, 이들 각각에 대하여 성능 결과를 측정한 후 가장 높은 성능을 발휘했던 hyperparameter 값을 최적값으로 선..
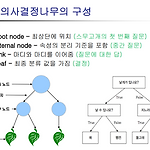 [ML수업] 3주차 이론2: decision tree (의사결정나무)
[ML수업] 3주차 이론2: decision tree (의사결정나무)
1. 의사결정나무(Decision Tree) 개요◼ 분류와 예측에서 자주 사용되는 강력하고 인기 있는 도구◼ 분류 결과를 인간이 쉽게 이해할 수 있는 규칙으로 표현 - 대출 상담자에게 대출을 해 줄 경우, 정확한 근거를 제시하여 대출을 거부할 자료를 제시할 수 있음 - If 연간 수입 $20,000이상 and 관련 계좌가 3개 이상 then 대출◼ 다수의 feature와 class 간의 관계에 대한 통찰을 얻을 수 있기 때 문에 데이터 탐색 과정에서도 널리 활용◼ 주요 의사결정나무 알고리즘 - Categorical class만 가능: C5.0, QUEST - Numeric & categorical class 모두 가능: CART, CHAID* scikit-learn의 ..
 [ML수업] 3주차 이론1: overfitting and regularization (과적합과 정규화)
[ML수업] 3주차 이론1: overfitting and regularization (과적합과 정규화)
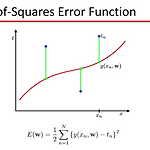
Sum of Suares Error function RMS RMS는 다음과 같은 단계를 거쳐 계산됩니다:제곱: 각 데이터 포인트 또는 신호의 값을 제곱합니다. 이는 모든 값을 양수로 만들어서 평균을 계산할 때 음수 값이 상쇄되지 않도록 합니다.평균: 제곱한 값들의 평균을 구합니다.제곱근: 평균 값을 다시 제곱근으로 변환합니다.수식으로 표현하면 다음과 같습니다: RMS 값이 높은 경우, 해당 신호나 데이터가 평균적으로 큰 값을 가지며 변동이 심하다는 것을 의미합니다. 반대로, RMS 값이 낮으면 신호나 데이터가 평균적으로 작고 변동이 적다는 것을 의미합니다. RMSE 축 설명:X축 (M): 모델의 복잡성을 나타냅니다. 이 경우, 모델의 차수(다항식 차수 또는 매개변수 수)로 이해할 수 있습니다. ..
 수학과 함께하는 AI 기초 - 파이선 프로그래밍 첫걸음
수학과 함께하는 AI 기초 - 파이선 프로그래밍 첫걸음
도서명: 수학과 함께하는 AI 기초 - 파이선 프로그래밍 첫걸음 저자 및 출판사: EBS 저 (한국교육방송공사) 이 책은 우리 일상 생활에서 발생하는 다양한 문제를 해결하기 위한 방법으로, 학교에서 배운 수학 지식을 바탕으로 파이선 인공지능 프로그래밍을 활용법을 소개한다. 3 개의 파트로 구성되어 있다. PART I. 인공지능의 발전 과정과 활용 방법, 수학과 어떤 연관 관계가 있는지를 담았다. PART II, 머신 러닝의 재료가 되는 다양한 생활 데이터, 이미지, 소리 데이터가 컴퓨터 과학에서 처리되는 과정과 이를 뒷받침하는 명제, 행렬, 수열, 삼각함수 등의 수학 개념을 소개한다. PART III, 데이터를 기반으로 한 머신 러닝 알고리즘을 적용하는 일상 사례를 소개한다. 각 사례에서 머신 러닝 알고..