
AI·빅데이터 융합 경영학 Study Note
[ML수업] 3주차 이론2: decision tree (의사결정나무) 본문
1. 의사결정나무(Decision Tree) 개요
◼ 분류와 예측에서 자주 사용되는 강력하고 인기 있는 도구
◼ 분류 결과를 인간이 쉽게 이해할 수 있는 규칙으로 표현
- 대출 상담자에게 대출을 해 줄 경우, 정확한 근거를 제시하여 대출을 거부할 자료를 제시할 수 있음
- If 연간 수입 $20,000이상 and 관련 계좌가 3개 이상 then 대출
◼ 다수의 feature와 class 간의 관계에 대한 통찰을 얻을 수 있기 때 문에 데이터 탐색 과정에서도 널리 활용
◼ 주요 의사결정나무 알고리즘
- Categorical class만 가능: C5.0, QUEST
- Numeric & categorical class 모두 가능: CART, CHAID
* scikit-learn의 DecisionTreeClassifier는 CART를 기반으로 구현
2. 의사결정나무의 구성

모든 의사결정나무 알고리즘들은 기본절차에 있어서 다음과 같은 공통점을 가지고 있음
| 목표변수 측면에서 부모노드보다 더 순수도(purity)가 높은 자식노드들이 되도록, 데이터를 반복적으로 더 작은 집단으로 나눈다(repeatedly split) |
3. 순수도와 분리기준

4. 나무 분리에 따른 순수도의 변화
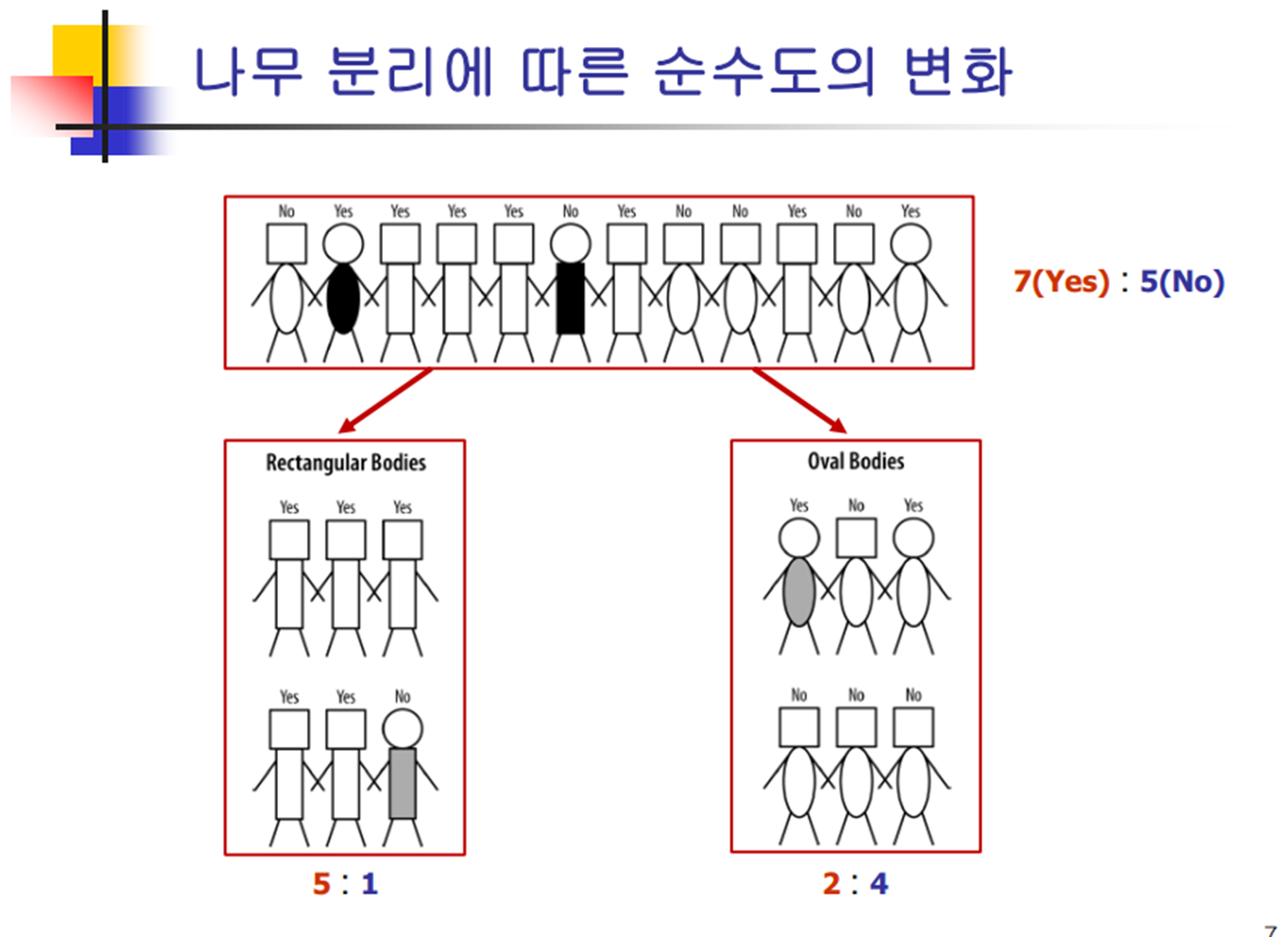
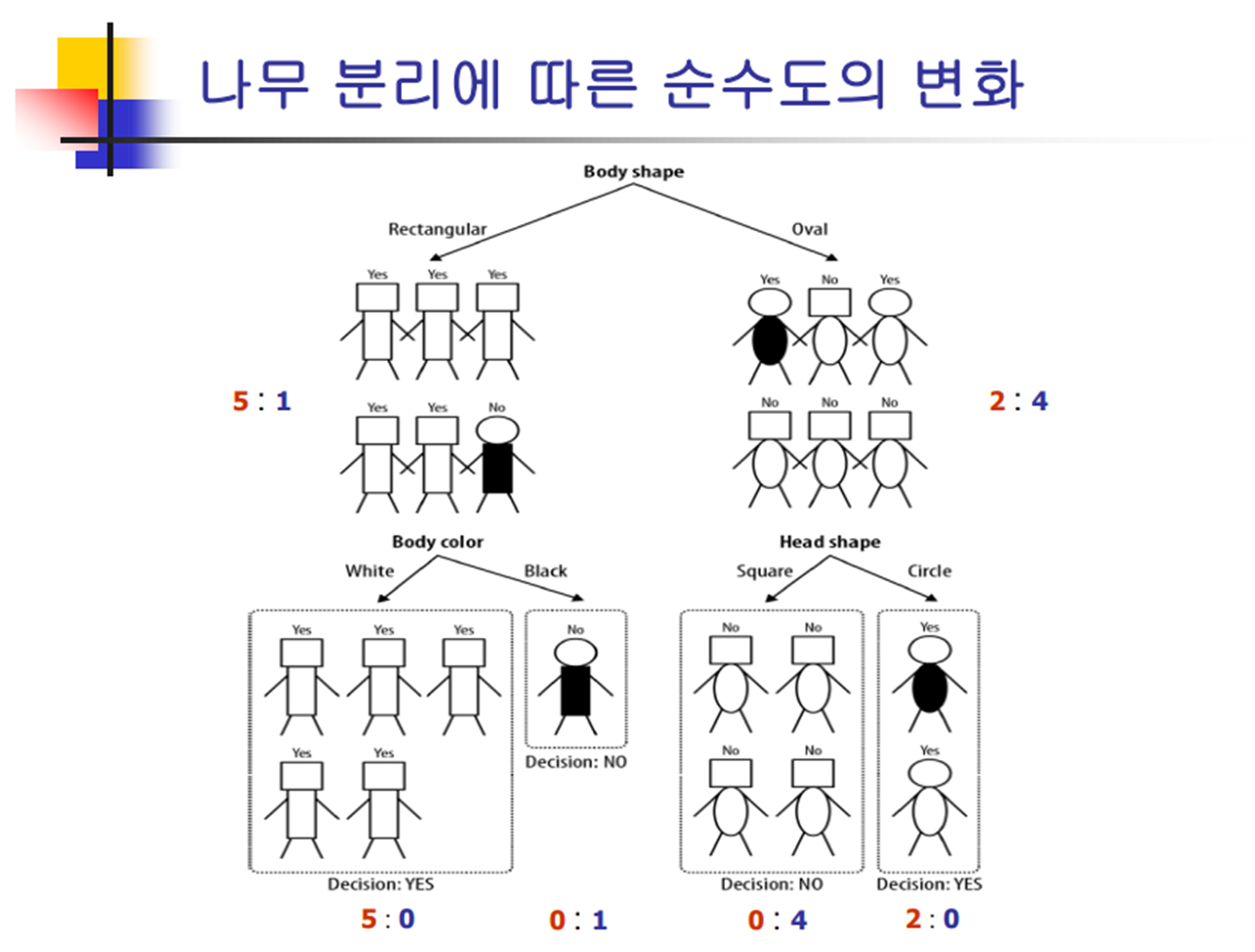
5. 순수도 척도

6. 엔트로피

7. 정보 이득(Information Gain)
( 정보 이득이 클수록 해당 기준에 따라 데이터를 분할하는 것이 예측에 더 유리하다는 것을 의미합니다. )
(지피티한테 " Information Gain 계산 예시를 들어줘"라고 물어보기)

8. 가지치기(Prunning)


'AI·ML' 카테고리의 다른 글
'AI·ML' Related Articles
more



