
AI·빅데이터 융합 경영학 Study Note
[논문리뷰]ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 본문
[논문리뷰]ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
SubjectOwner 2026. 5. 19. 14:00https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Abstract
트랜스포머 구조는 NLP 분야에서 실질적으로 (de facto) 표준적인 모델일 때 Comupter vision 분야에서는 제한적으로 사용되었다. 기존에는 attention와 convolution을 함께 사용했다. 하지만 본 논문에서는 attention만 가지고도 신뢰할 수 있는 이미지 분류 결과를 얻었음을 보인다. 이는 attention이 이미지의 패치 (patch, 작은 조각)의 시퀀스를 학습하게 함으로써 달성한다. 우리는 이 모델을 ViT (Vision Transformer)라고 부른다.
- 예전에는 CNN + Attention 형태로 일부만 attention을 사용했는데 어텐션만 쓰는 걸 성공한거임!!
- 원래 Transformer는 “순서가 있는 데이터(sequence)”를 처리하는 모델임. 이미지를 “패치들의 시퀀스(sequence)”로 바꿔서 처리함.
3. Method

ViT의 기본 구조는 Figure 1과 같다.
Input Size and Tensor Shape
본래의 표준적인 트랜스포머는 토큰 임베딩으로 구성된 1D 시퀀스를 입력으로 받는다.
하지만 이미지는 2D이므로 image

를 다음과 같은 과정으로 정제한다.
- H: 이미지 높이(height)
- W: 이미지 너비(width)
- C: 채널 수(channel)
- 는 H×W×C 크기를 가지는 실수값 텐서이다
- 이미지로 생각하면 H=224, W=224, C=3이면 RGB 컬러이미지라서 x∈R224×224×3 이 된다.
이미지 패치를 flatten하여 다음처럼 크기를 변환한다.

이때 는 이미지 패치의 해상도이며 는 원본 이미지의 해상도다. 그리고 는 채널의 수다.
예를 들어 P=16이면 16×16 크기의 패치로 분할한다.
가로 방향 파치 수 = W/P
세로 방향 파치 수 = H/P
따라서 패치의 수는 로 계산된다.
이때 이미지의 raw data를 사용하는게 아니라 하나의 학습가능한 linear projection 레이어를 통해서 패치 임베딩을 생성하고(즉, Patch→Flatten→Linear Projection→Patch Embedding(768→D로 변환하는거) 순서이다.) 이를 Transformer encoder에 넣는다.
ViT에서는 모든 latent vector와 layers에 대해서 constant vector size인 를 사용한다.
Special Token
BERT와 유사하게 sequence의 맨 앞에 [class] 토큰을 덧붙인다.
[CLS] I love cats 이런 식으로.
Transformer를 통과한 후에는
- I 정보
- love 정보
- cats 정보
가 모두 [CLS] 토큰에 모이게 됩니다.
그래서 BERT는 마지막에 [CLS]만 꺼내서
- 긍정/부정 분류
- 스팸 분류
- 문장 분류
를 수행합니다.
ViT도 똑같이 합니다.
원래 patch sequence가
[z1,z2,z3,⋯ ,zN] 이라면
맨 앞에 [CLS] 토큰을 추가해서 [CLS,z1,z2,z3,⋯ ,zN] 를 Transformer에 넣습니다.
이 class head에 대한 MLP는 pre-training 단계에서는 숨기고, fine-tuning 단계에서 하나의 레이어로 [class] 토큰에 대한 라벨을 예측한다.
논문에는 말이 좀 어렵게 쓰여져있는데 ViT 설명 한국어 (링크)에 보면 그냥 Transformer encoder를 통과한 다음 [class] 토큰에 MLP를 적용해서 클래스를 예측한다는 이야기다. Figure 2만 보는게 차라리 더 이해하기 쉬운거 같다.
Positional embeddings는 1D 포지션 임베딩을 적용했다.
2D-aware 포지션 임베딩도 수행했으나 성능적인 향상을 볼 수 없었으며 이는 Appendix D에 첨부했다.
Patch Embedding과 Position Embedding을 더해서 Transformer Encoder에 보낸다.
Final Input
Flatten, projection, adding special token, positional embeddings를 모두 사용한 최종 input 은 다음과 같다.
는 embedding matrix를 나타낸다. 그리고

그리고 이 수식은 ViT에서 Transformer Encoder에 실제로 들어가는 최종 입력 z0z_0 를 만드는 과정이다.
Patch Embedding Matrix
: 패치 개수
+1: CLS 토큰
예를 들어
224×224 이미지
16×16 patch
이면
N=196N=196
이므로
N+1=197
입니다.
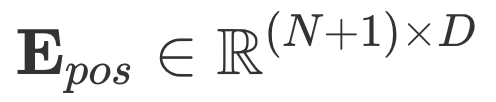
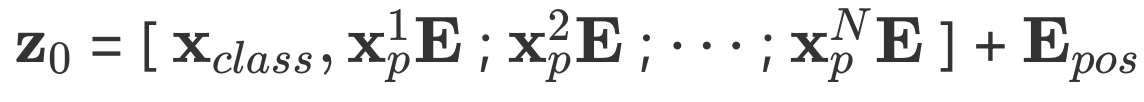
Transformer Encoder Block
Encoder block은 Multi-Head Self-Attention(MSA)과 FFN (MLP)로 이루어진다.
FFN의 경우 MLP와 GELU로 구성된다.
GELU는 ReLU의 개선판으로, 음수를 갑자기 잘라내지 말고 부드럽게 줄인다.
그리고 Layernorm (LN)은 모든 블록에 적용되며 residual connections는 모든 블록을 거친 다음에 적용된다.
Input
↓
LN
↓
MSA
↓
Residual Add
↓
LN
↓
MLP
↓
Residual Add
↓
Output 이런 느낌스
멀티해드 셀프 어텐션이 ViT의 핵심인데,
이미지의 눈 부분 패치를 코 패치가 얼마나 참고해야 할까를 계산한다.
즉, 모든 패치 ↔ 모든 패치
관계를 학습한다.
그래서 멀리 떨어진 위치도 연결할 수 있다.
이를 논문에서
Self-Attention이 Global Feature를 학습한다
라고 표현한다.
Inductive Bais
CNN은 2차원에서 인접한 locality를 학습하지만 ViT의 경우 self-attention이 global feature를 학습하고 MLP가 local을 학습하기 때문에 다르다.
Fine-tuning
ViT는 대규모 데이터셋에 pre-train한 다음에 상대적으로 작은 downstream tasks에 파인 튜닝한다. (작은 데이터셋으로 재학습한다.) Pre-train 후 Higher resolution에 파인튜닝을 하는데 이때도 패치의 크기는 동일하다. 하지만 pre-trian에서 수행했던 position embeddings의 의미가 없어진다. (라고 직역이 되는데, 실제 뜻은 pre treained 결과와 fine tuning 결과의 패치 개수가 달라지낟.) 이를 해결하기 위해서 pre-trained 포지션 임베딩에 2D interpolationd을 수행한다. 어떻게 수행하냐? 보간(interpolation) 을 해서 늘린다고 한다..
즉 실제 구조는:
이미지
→ patch 분할
→ flatten
→ patch embedding
→ position embedding 추가
→ Transformer Encoder
→ [CLS] 토큰 추출
→ MLP
→ 클래스 예측
입니다.
4. Experiments
Datasets
ILSRVRC-2012 ImageNet에는 총 1k class가 있으며 1.3M 이미지가 있다.
JFT 데이터는 총 18k의 클래스가 있고 303M high-resolution 이미지가 있다.
Downstream 데이터는 다음과 같다. ReaL labels, CIFAR-10 / 100, Oxford-IIIT Pets, Oxford Flower-102, VTAB classification tasks다.
Model Variants
ViT는 Base, Large, Huge의 세 가지 사이즈가 있다.
자세한 내용은 아래 Table 1에 명시되어 있다.

Training and Fine-Tuning
Adam을 사용했으며 은 0.9, 는 0.999다. 배치 사이즈는 4096이며 weight decay는 0.1로 설정했다.

ViT-Huge를 JFT에 대해 pre-train 했을 때 좋은 성능임을 알 수 있다.

VTAB에 대한 ViT의 크기별 성능이다. 클수록 성능이 좋다.

Figure 3, 4, 5는 ViT와 ResNet의 성능을 비교한다.
Appendix D
D. 4 Positional Embedding
No positional Embeddings: 패치들의 묶음
1D positional Embeddings: 하나의 시퀀스
2D positional Embeddings: D/2 사이즈의 X축 임베딩과 Y축 임베딩을 concat하여 사용
Relative positional Embeddings: 모든 패치의 쌍 (pairs)에 대해서, 구체적으로는 (q, k/v) 페어들이다. (q_1, k_2), (q_1, k_3), ..., (q_1, v_2), ... (q_1, v_3), ... ), 에 대해서 offset pq을 구한다. 저자들은 단순히 추가적인 attention을 수행했다고 한다.
포지션 임베딩들의 비교 실험 결과는 아래의 Table 8에 있다.
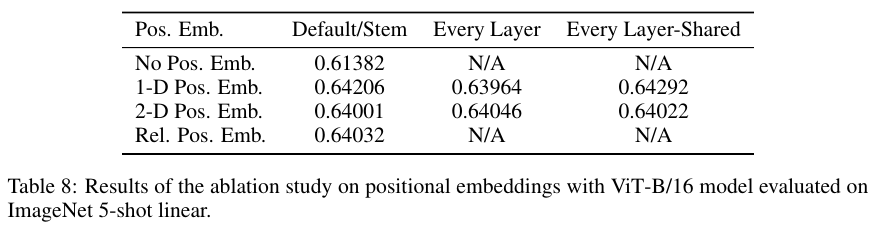
1D를 기준으로 했을 때 포지션 임베딩이 없는 경우를 제외하고는 큰 차이가 없음을 알 수 있다.
저자들은 원본 이미지 224 x 224 같이 위치의 차이가 큰 경우 포지션 임베딩이 중요하지만,
패치의 경우 16 x 16과 같이 위치의 차이가 작기 때문에 포지션 임베딩의 방법이 상대적으로 덜 중요하다고 추측하고 있다.
참고자료
https://arsetstudium.tistory.com/200
ViT Vision Transformer(2021) 논문 리뷰
ViT (Vision Transformer) 모델의 논문 이름은 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale다. (링크) 저자는 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas
arsetstudium.tistory.com
'AI·ML' 카테고리의 다른 글
| [논문리뷰]T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (0) | 2026.05.19 |
|---|---|
| [논문리뷰]VAE: Auto-Encoding Variational Bayes (1) | 2026.05.17 |
| [논문리뷰] SPPnet 'Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition' (0) | 2026.05.11 |
| [논문리뷰]Transformer (1) | 2026.05.03 |
| [논문리뷰] ELMo(Deep contextualized word representations) (0) | 2026.04.29 |
