
AI·빅데이터 융합 경영학 Study Note
[논문리뷰]BERT (양방향!!) 본문
https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
0. Abstract
BERT는 unlabeled data로 부터 pre-train을 진행 한 후, 이를 특정 downstream task(with labeled data)에 fine-tuning(transfer learning)을 하는 모델이다.
논문에서 deep bidirectional이란 단어가 많이 등장하는데, Bidirectional LSTM이나 ELMo와 같은 모델에서 bidirectional이란 키워드를 사용하긴 했으나, BERT에서는 deep bidirectional의 deep을 더욱 강조하여 기존의 모델들과의 차별성을 강조한다.
(deep bidirectional이 기존의 bidirectional(shallow bidirectional, unidirectional)과는 무엇이 어떻게 다른지는 아래에서 자세하게 설명하겠다)
또한, 하나의 output layer만을 pre-trained BERT 모델에 추가하면 Question Answering, Language Inference 등과 같은 NLP의 다양한 주요 task(총 11개)에서 SOTA를 달성 할 수 있다고 말한다.
(이는 pre-trained BERT모델의 확장성이 넓고, 그 성능 역시 기존의 모델들을 훨씬 뛰어넘는다는 것을 의미)
1. Introduction

Language model(LM)의 pre-training 방법은 BERT 이전에도 많이 연구되고 있었고, 실제로 굉장히 좋은 성능을 내고 있었다.
특히 문장 단위의 task(NLI 등)에서 두각을 보였는데, 이러한 연구들은 두 문장의 관계를 전체적으로 분석하여 예측하는 것을 목표로 한다.
또한 문장 뿐만 아니라 토큰 단위의 task(개체명 인식, QA 등)에서도 역시좋은 성능을 보였는데, 이러한 모델은 token 단위의 fine-grained output을 만들어 내야한다.
여기서, fine-grained output이란 하나의 output을 내기 위해 작은 단위의 output 프로세스로 나눈 뒤 수행하는 것을 의미한다.
이때, down stream task에 pre-trained language representation를 적용하는 방법은 크게 두 가지가 존재한다.
첫번째는 feature based approach다.
대표적으로 ELMo가 있는데, ELMo는 pre-trained representations을 하나의 추가적인 feature로 활용해 (down stream) task-specific architecture를 사용한다.
두번째는 fine-tuning approach이다.
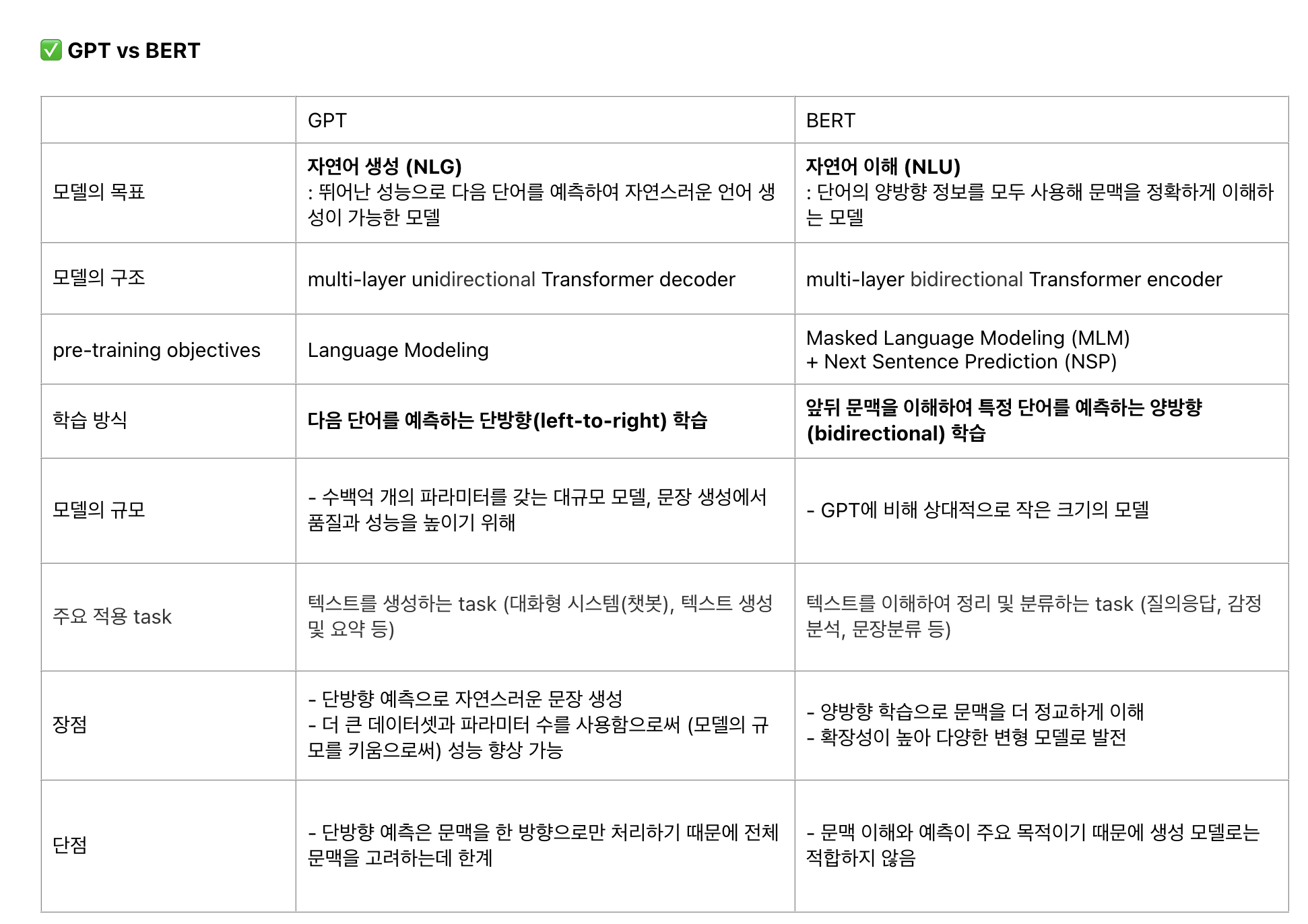
Fine-tuning approach의 예는 OpenAI의 GPT(Generative Pre-trained Transformer)가 있다. GPT는 task-specific(fine-tuned) parameters 수 는 최소화하고, 모든 pre-trained 파라미터를 조금만 바꿔서 down stream task를 학습한다.
💡ELMo가 순방향 언어 모델과 역방향 언어 모델을 모두 사용하기 때문에 Bidirectional lanuage model이라고 생각할 수 있지만, ELMo는 각각의 단방향(순방향,역방향) 언어모델의 출력값을 concat해서 사용하기 때문에 하나의 모델 자체는 단방향이다. 이것이 바로 BERT에서 강조하는 deep bidirectional과의 차이점이라고 할 수 있다.
논문에서는 기존의 방법(feature based, fine-tuning approach) 특히 fine-tuning 방법이 representation pre-training의 성능을 떨어뜨린다 말한다.
그 예시로 GPT의 단점에 대해 말하는데, GPT와 같은 단방향 language model의 경우 모든 토큰이 이전 토큰과의 attention만 계산하므로 문장 수준의 task에서는 sub-optimal(차선책)이 된다고 한다.
또한 QA와 같은 토큰 단위의 task에서는 context의 양방향을 포함하는 것이 굉장히 중요한데, fine-tuning based 접근을 사용하면 성능이 매우 떨어진다.
Masked Language Model(이하 MLM)은 랜덤하게 입력 토큰의 일부를 마스킹시키고, 해당 토큰이 구성하는 문장만을 기반으로 그 마스킹된 토큰들의 원래 값을 정확하게 예측하는 것이 목적이다.
단방향 언어 모델의 사전학습과는 다르게, MLM는 양방향 context를 융합시켜 deep bidirectional Transformer를 가능하게 한다. 게다가, MLM에서 text-pair representations로 pretrain하면 "Next sentence prediction" task도 적용할 수 있다.
2. Related Work
이번 섹션에서는 language representation을 pre-training하는 방법론(feature based, fine tuning, transfer learning)들의 긴 역사를 대표적인 것들만 간단하게 리뷰한다.
ELMo와 그 후속 모델들은, 전통적인 word embedding 연구에서 한 층 더 발전하였는데, 바로 left-to-right와 right-to-left 언어 모델을 통해 context-sensitive feature들을 뽑아내는 방식이다.
이렇게 생성된 토큰 별 contextual representation은 left-to-right, right-to-left representation의 단순 concat이다.(shallow bidirectional)

left-to-right, right-to-left language model을 단순히 concat한 ELMo
이렇게 단순 concat하는것 만으로도 ELMo는 주요 NLP benchmarks(QA, 감성분석, 개체명 인식 등)에서 SOTA를 달성했다. 그러나 이러한 모델들은 deep bidirectional하지는 않다.
2-2. Unsupervised Fine-tuning Approaches
초기 feature-based approaches에 대한 연구는 unlabeled text로 부터 word embedding parameter를 pre-training하는 방향으로 진행되었다.
최근에는, contextual token representation을 만들어내는 (문장 혹은 문서)인코더가 pre-training되고, supervised downstream task에 맞춰 fine-tuning된다.
이러한 접근방식의 장점은 scratch로(처음부터) 학습하는데 적은 파라미터로 충분하다는 것이다.
GPT 역시 이러한 방식을 사용하여 다양한 문장 단위 task에서 SOTA를 달성 할 수 있었다.
2-3. Transfer Learning from Supervised Data
또한 기계번역(Machine Translation)과 자연어추론(NLI) 대규모 데이터셋으로부터의 효과적인 전이학습(Transfer Learning)을 보여주는 연구도 있다.
전이학습은 자연어처리 뿐만 아니라 CV(Computer Vision) 연구에서도 그 중요성이 강조되는데, ImageNet 등을 활용해 사전학습을 한 모델이 성능이 좋다고 한다.
3. BERT
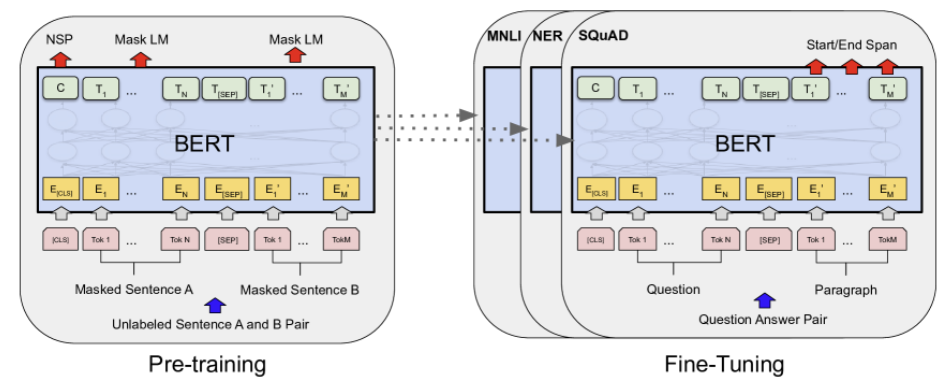
논문에서는 BERT를 Pre-training part와 Fine-tuning part로 나누어 설명한다.
BERT의 전체 학습 절차는 크게 두 단계다. 첫 번째는 unlabeled text를 이용한 pre-training이고, 두 번째는 task-specific labeled data를 이용한 fine-tuning이다. 중요한 점은 pre-training과 fine-tuning에서 거의 동일한 architecture를 사용한다는 것이다. downstream task마다 복잡한 구조를 새로 설계하는 대신, BERT 위에 아주 작은 output layer만 추가하고 전체 파라미터를 fine-tuning한다.
이 구조는 GPT-1의 pre-training/fine-tuning 흐름과 닮아 있지만, 결정적인 차이는 attention 방향성이다. GPT는 decoder-style left-to-right self-attention을 사용한다. 반면 BERT는 Transformer encoder를 사용하므로 입력 sequence의 모든 token이 서로를 양방향으로 attend할 수 있다.

이 그림을 보면 BERT의 철학이 매우 명확하다. 다양한 downstream task를 위해 task-specific architecture를 크게 바꾸지 않는다. MNLI, NER, SQuAD처럼 입력과 출력 형식이 다른 task도 모두 같은 BERT backbone으로 처리한다. 모델 하나를 범용 언어 이해 backbone으로 만들고, task에 따라 입력과 output layer만 바꾸는 방식이다.
2) Model Architecture
- multi-layer bidirectional Transformer encoder
- L : the number of layers
- H : the hidden size
- A : the number of self-attention heads
- BERT_BASE : L=12, H=768, A=12, Total Parameters=110M
(OpenAI GPT와 비교하기 위해 동일한 model size로 설정) - BERT_LARGE : L=24, H=1024, A=16, Total Parameters=340M
3) Input/Output Representations
- WordPiece embeddings, 30,000 token vocabulary 이용
- Sentence = Span of contiguous Text = Single Sentence이거나 Sentence 쌍을 하나로 묶은 형태
- sentence 쌍을 하나로 묶는 경우 두 sentence를 구분하기 위해
① 두 문장 사이에 [SEP] 토큰을 추가하고
② 모든 토큰에 문장 A에 속하는지 문장 B에 속하는지를 나타내는 임베딩을 추가
- [CLS] : 모든 sequence의 시작에 추가되는 토큰
- [SEP] : 연결된 sentence pairs 사이를 구분하는 토큰
- E : input embedding
- C : the final hidden vector of the special [CLS] token
- T_i : the final hidden vector for the i-th input token
∴ BERT input representation
= Token embedding + Segment embedding + Position embedding
- Token embedding : 각 token에 대한 embedding
- Segment embedding : 해당 token이 어느 sentence에 포함되어있는지 알려주는 embedding
- Position embedding : Transformer 구조에서 사용되는, 위치 정보를 담고 있는 embedding

▶ 3.1 Pre-training BERT
- pre-train BERT using two unsupervised tasks
- pre-training corpus : BooksCorpus (800M words), Wikipedia (2,500M words)
1) Task #1: Masked LM
- input 토큰들 중 일정 비율의 토큰을 무작위하게 mask한 후 mask된 토큰을 예측하는 과정
- mask 토큰에 대응하는 final hidden vectors를 softmax에 적용해 가장 확률이 높은 토큰으로 예측
- 이 논문에선 각 문장에 있는 WordPiece tokens을 15% 비율로 무작위 mask
- 이때 pre-training에서 사용한 [MASK] token이 fine-tuning에는 존재하지 않아 불일치 문제 발생
- 15%의 mask token들을 3가지 방법으로 사용 (모두 예측의 대상임)
- 80% : [MASK] 토큰으로 변경
- 10% : 임의의 다른 토큰으로 대체
- 10% : 기존의 토큰을 그대로 사용
- 예시 : my dog is hairy 문장에서 'hairy'를 mask
→ my dog is <MASK> / my dog is apple / my dog is hairy
2) Task #2: Next Sentence Prediction (NSP)
- setence A 뒤에 sentence B가 올 수 있는지 없는지 예측하는 binary next sentence-prediction
- 모델이 sentence relationships를 학습하기 위해 진행
- pre-training example에서 두 sentences A와 B 선택
- 50% : A와 B가 관련된 문장, A뒤에 B가 따라오는 문장, 'IsNext'라고 labeling
- 50% : A와 B가 관련없는 문장, 무작위 선택, 'NotNext'라고 labeling
→ [CLS] A [SEP] B 형태로 이어 붙혀 input sequence로 사용
→ [CLS] token의 final hidden vector C를 feed-forward network에 통과시키고
softmax에 넣어 isNext와 NotNext에 대한 확률 값 계산
* [CLS] token의 final hidden vector C
: 문장의 전체 의미를 요약하는 벡터, sequence의 결합된 의미를 가지는 역할
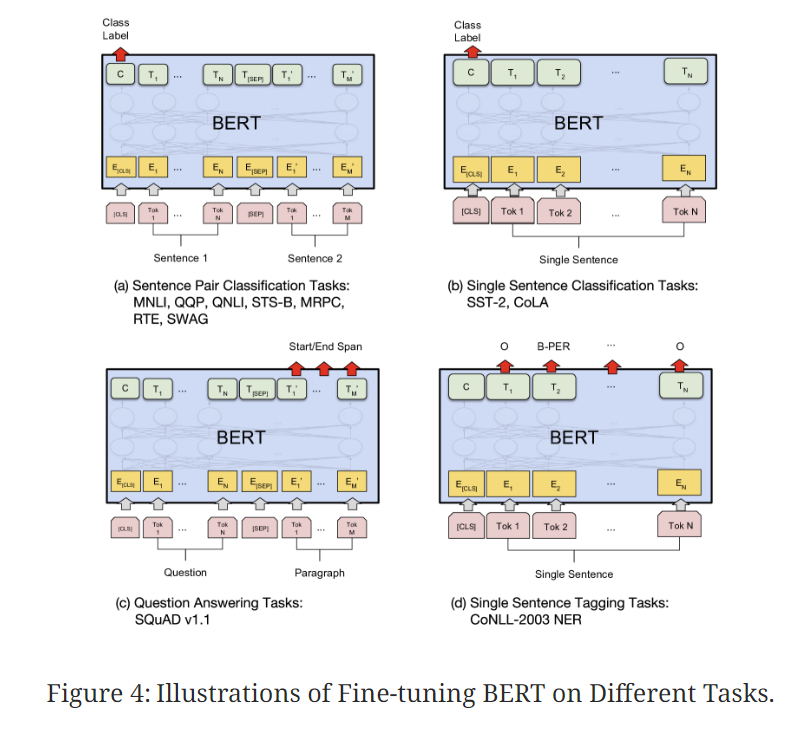
▶ 3.2 Fine-tuning BERT
- pre-trained BERT 모델에 task-specific labeled data를 넣어 파라미터를 fine-tuning
- classification tasks : [CLS] token의 final hidden vector C를 output layer에 입력하여 fine-tuning
Natural Language Inference, sentiment analysis - token-level tasks : final layer의 token representations를 output layer에 입력하여 fine-tuning
sequence tagging, question answering)
[참고 자료]
[최대한 자세하게 설명한 논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- References https://arxiv.org/abs/1810.04805?source=post_page (논문 원본) 해당 포스팅은 BERT 논문을 자세히 읽으며 공부한 내용들을 논문의 목차 순서대로 정리한 것이다. 0. Abstract BERT가 unlabeled text로부터 deep
hyunsooworld.tistory.com
https://working-helen.tistory.com/99
[NLP 학습] 2주차 : BERT / 논문 리뷰 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
이전 포스트에서 다룬 Transformer의 개념을 바탕으로 BERT에 대해 학습해본다. BERT와 관련된 논문 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"를 리뷰한다. 1. BERT 2. 논문 리뷰
working-helen.tistory.com