
AI·빅데이터 융합 경영학 Study Note
[논문리뷰]GPT-1 (대규모 텍스트 사전 학습의 시작) 본문
1. GPT-1
- OpenAI에서 2018년에 발표한 “Improving Language understanding by Generative Pre-Training" 논문에서 제안된 모델
- Generative Pre Training of a language model
- 자연어 처리 분야에서 전이 학습의 가능성을 처음으로 입증한 모델 중 하나
- 이후 GPT-2, GPT-3, GPT-4와 같은 후속 모델들로 이어짐
1) GPT-1 등장 배경
- 기존의 NLP 모델은 대부분 supervised learning 방식을 사용했지만,
NLP task에서 labeled data를 충분히 확보하기 쉽지 않고 사람의 labeling은 비효율적
- 이와 달리 unlabeled data는 대규모로 존재하지만 효과적으로 활용할 수 있는 방법이 부재
- 또한 각각의 NLP 모델은 특정한 task에 맞춰서 설계되었기 때문에
서로 다른 task에 대해서 새로운 모델을 학습시켜야하는 문제
➡️ GPT-1
= unsupervised learning으로 generative pre-training 모델을 먼저 학습,
→ supervised learning으로 각각의 task에 specific한 discriminative 모델로 fine-tuning
= 대규모 unlabeled data에서 학습한 Transformer 기반의 generative pre-training 모델
→ 비교적 적은 labeled data에서 학습한 downstream task discriminative 모델
= 대규모 unlabeled data를 활용함으로써 모델의 성능을 높이는 동시에
전이학습을 도입함으로써 약간의 변형만 가지고도 다양한 NLP tasks로 transfer할 수 있음
==> unlabeled data에서 학습된 generative pre-training 모델을 전이학습함으로써
다양한 자연어 처리 작업에서, 적은 양의 labeled data로도 높은 성능을 달성할 수 있는 모델
GPT-1 논문의 의의
- 대규모 unlabeled data를 활용할 수 있는 모델
- NLP 분야에 전이학습을 도입
2) GPT-1 의 구조
- multi-layer Transformer decoder 구조
= Transformer에서 encoder는 제외하고 decoder만을 가져온 구조
- tokens embedding(W_e)→ potision encoding(W_p)
→ n개의 decoder layer를 통과
→ masked multi-head self-attention → Residual connection + Layer Normalization
→ feed forward → Residual connection + Layer Normalization
→ linear + softmax layer → output probabilities

① BPE(Byte-pair encoding)
- subword-based tokenization, subword segmentation
- 텍스트를 단어가 아닌 subword 단위로 분할, 하나의 단어를 여러 서브워드로 분리하여 encoding
(예: birthday = birth + day로 분리)
- OOV(Out-Of-Vocabulary) 문제를 완화할 수 있음
- 가장 많이 등장한 글자의 쌍을 찾아 병합하는 과정을 연속적으로 진행
step 1. 훈련 데이터에 있는 단어들을 문자 단위로 분리해 vocabulary 구성

출처 : https://wikidocs.net/22592
step 2. vocabulary 문자들로 연결된 문자쌍 각각의 빈도수를 계산
step 3. 빈도수가 가장 높은 문자쌍을 병합하여 vocabulary에 추가
(빈도수가 9로 가장 높은 (e, s) 쌍을 es로 병합하여 vocabulary에 추가)

step 4. 원하는 vocabulary 크기에 도달할 때까지 문자쌍을 추가하는 과정을 반복
(빈도수가 9로 가장 높은 (es, t) 쌍을 est로 병합하여 vocabulary에 추가)

==> 기존에 없던 단어 ' lowest'가 입력되었을때 이를 <UNK> 처리하는 것이 아니라
vocabulary에 있는 'low'와 'est'로 구분하여 encoding

출처 : https://wikidocs.net/22592
* OOV(Out-Of-Vocabulary) 문제
언어 모델은 자신이 모르는 단어가 등장하면 이를 <UNK>로 인식하는데, 이때 모델이 모르는 단어가 너무 많아져 문제 해결에 어려움을 겪는 것을 OOV 문제라고 한다.
② unsupervised pre-training
- 대규모 unlabeled data를 사용, Next Word Prediction task 수행
- standard language modeling objective 이용
➡️ 일반적인 언어 구조, 문맥, 패턴 등을 학습
③ supervised fine-tuning
- 적은 수의 labeled data를 사용, 각각의 specific task 수행
- auxiliary objective = target task objective + auxiliary unsupervised training objective 이용
- pre-training에서 학습한 모델을 초기 파라미터로 이용
- 각각의 task에서 사용되는 dataset의 형태를
pre-training한 Transformer 모델의 input 형태로 변환해주는 과정 필요
➡️ 전이학습으로 specific task에서 높은 성능 달성
-------------이제부터 논문 리뷰 -----------------------
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Improving Language Understanding by Generative Pre-Training
✏️ 논문 내용 정리
- GPT-1 모델 고안 배경
: NLP의 다양한 task에서 unlabeled data는 풍부하게 존재하지만,
supervised learning에 필요한 labeled data는 매우 부족하다는 문제점
- GPT-1 모델과 이전 모델의 차이점
" using a combination of unsupervised pre-training and supervised fine-tuning "
: 대규모 unlabeled data를 사용해 language modeling task를 수행하는 unsupervised pre-training 모델을 먼저 학습한 후, labeled data를 사용해 이를 각각의 task에 specific하게 fine-tuning
- GPT-1 의 구조
= multi-layer Transformer decoder
= 기존의 Transformer 구조에서 decoder만을 가져와 사용
① Unsupervised Pre-Training : standard language modeling objective
② Supervised Fine-Tuning : auxiliary objective
= target task objective + auxiliary unsupervised training objective
- 논문에서 보인 모델 특성
① 12개의 NLP task dataset 중 9개 데이터 세트에서 새로운 sota 달성
② pre-trained 모델의 layer를 많이 사용할수록 fine-tuning 모델도 성능이 좋아짐
③ pre-training을 많이 진행할수록 fine-tuning 이후의 성능이 좋아짐
▶ 0. Abstract
- unlabeled text data는 풍부한 것에 비해, NLP 모델 학습에 필요한 labeled data는 부족
- 이 논문에선 언어모델을 대규모 unlabeled text data를 기반으로 generative pre-training한 후 각각의 특정한 task에 대하여 discriminative fine-tuning하는 방식이 매우 유용함을 보임
- fine-tuning 과정에서 각각의 task마다 적합한 입력 형태로 task-aware input transformations하는 과정을 사용함으로써 모델 아키텍처를 최소한으로 변경하면서도 효과적으로 transfer
- 실험 결과 새롭게 제안한 general task-agnostic model은 각 task에 대하여 discriminatively trained models보다 더 성능이 뛰어남
2. Related Work
1) Semi-supervised learning for NLP
Sequence labeling, text classification 등 과제에서 큰 각광을 받았다. 그러나 이전까지의 연구에서는 '단어' 단위로만 활용되었기 때문에 본 논문에서는 구, 문장 level의 수준으로 활용하고자 한다.
2) Unsupervised pre-training
'Good initialization point'를 찾는 과정이며, 이미지 분류, 음성 인식 등의 분야에서 좋은 성과를 보였다. 자연어 처리 분야에서도 신경망을 pre-training 하는 선행 연구가 존재하는데, 이는 LSTM 구조를 사용하였기에 긴 문장 처리에서 어려움이 있었다. 따라서 본 논문에서는 Transformer를 활용하였고, 다양한 분야에서 최소한의 변형으로도 좋은 성능을 낼 수 있었다.
3) Auxiliary training objectives
보조 목적 함수를 target task 목적 함수에 추가하는 것은 성능 면에서 증명된 방법이다. 본 논문에서도 역시 supervised learning 단계에서 보조 목적 함수를 추가한다.
3. Framework
훈련 과정:
1) 대규모 text corpus로 LM 학습
2) labeled data로 각 task에 맞게 fine-tuning
3-1. Unsupervised pre-training
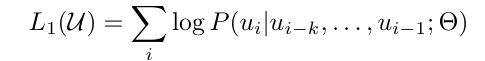
학습 목적 함수는 NLP 분야에서 흔히 볼 수 있는 log-likelihood 최대화 함수이다. 즉, 이전 k개의 단어들을 보고 다음 단어를 예측하게 되는 next-word prediction 형태이다.
여기서 language model로 GPT-1은 Transformer의 디코더 부분만을 여러 레이어로 사용한다.

Next-word prediction 방식으로 학습을 하기에 디코더 구조가 적합하며, 모델 구조가 좀 더 간결해져 연산량의 이점도 존재한다.

위 구조에서 볼 수 있듯 디코더 레이어를 12개 쌓았으며, 인코더를 사용하지 않기 때문에 기존의 encoder-decoder attention (cross attention) 부분은 사용하지 않는다.
3-2. Supervised fine-tuning
이제 labeled data로 parameter 조정 단계를 거치는데, 사전 학습된 모델에 input을 넣어 최종 출력 을 얻는다. 그 후 linear layer 를 통과시켜 y에 대한 예측값을 얻어 마찬가지로 log-likelihood 최대 함수를 계산한다.

여기에 3-1의 pre-training loss를 보조 목적 함수로 더하여 최종적인 fine-tuning loss를 계산한다.

3-3. Task-specific input transformations
지금까지 설명한 구조는 text classification task에 적용되는 것이다. 만약 다른 task를 위해 fine-tuning 한다면 어떻게 조정해야 할까?
앞서 설명했듯이 GPT-1은 최소한의 input 구조 변화로 전이 학습이 가능하게 한다. Traversal-style approach라고 하며, 모델 구조 자체를 바꾸는 것이 아니라 각 task에 맞는 구조화된 입력 (structured input)을 사용한다.

1) Text classification task
단순 텍스트 분류 문제로, 전체 문장이나 글을 입력으로 넣으면 된다.
2) Textual entailment task
전제 (premise)와 가정 (hypothesis), 두 문장과 중간에 문장 구분자 (delim)를 함께 입력 받는다. 두 문장 사이의 관계를 분류하게 된다.
3) Similarity task
두 문장이 얼마나 유사한지 측정하는 문제다. 이때는 두 문장의 순서가 관계없기 때문에 순서가 바뀐 두 입력 시퀀스를 받아 마지막에 eliment-wise addition 해준다.
4) Question Answering and Commonsense Reasoning task
지문 z, 질문 q, 그리고 정답 리스트 {}가 주어지는 문제로, 특정 질문에 대한 정답을 고르는 문제다. 이 경우 z, q, {a_k}를 구분자로 연결한 여러 시퀀스를 독립적으로 입력한다. 그 이후 softmax 연산으로 가장 정답 분포에 가까운 답을 선택한다.
[참고 자료]
https://working-helen.tistory.com/98
[NLP 학습] 2주차 : GPT-1 / 논문 리뷰 : Improving Language Understanding by Generative Pre-Training
이전 포스트에서 다룬 Transformer의 개념을 바탕으로 GPT-1에 대해 학습해본다. GPT-1과 관련된 논문 "Improving Language Understanding by Generative Pre-Training"를 리뷰한다. 1. GPT-1 2. 논문 리뷰 1. GPT-1 - Ope
working-helen.tistory.com
[논문 리뷰 & 코드 구현] GPT-1 (Improving Language Understanding by Generative Pre-Training)
Transformer의 발표 이후 NLP 분야의 발전 속도는 가히 엄청났다. Transformer 구조를 활용하여 엄청난 양의 데이터를 학습하기 시작했고, 현재의 LLM (Large Language Model) 열풍으로까지 이어졌다. 그 중 대
velog.io