
AI·빅데이터 융합 경영학 Study Note
논문 리뷰_VGG (VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION) 본문
논문 리뷰_VGG (VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION)
SubjectOwner 2024. 4. 30. 23:56https://ar5iv.labs.arxiv.org/html/1409.1556
참고 사이트

요약
[Summary]
깊이 증가시키며(16-19 Layers) 성능 향상
모든 Conv LAYER에서 3x3 filter 사용 → 파라미터수 줄여 연산량 감소
[Abstract]
We investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. 대규모 이미지 인식 설정에서 컨볼루션 네트워크 깊이가 정확도에 미치는 영향을 조사한다.
Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small ( 3 × 3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16–19 weight layers.
Depth로 Accuracy를 향상시키는 방법
최소 크기의 Filter(3x3)을 사용하면서 Depth를 증가시켜 성능 향상
이 때 Depth는 16-19
[Introduction]
Conv Net 효과 발전, 성능 향상 위한 다양한 시도 있었다.
본 논문은 구조 설계 시 Depth에 집중
더 많은 Conv Layer를 추가했다
이는 모든 Layer에 3x3 Filter를 사용했기에 가능
[2 CONVNET CONFIGURATIONS 구성]
[2.1 ARCHITECTURE] (기본 설정. 수업 영상에 자세히 나옴.)
- Input = 224x224 RGB Image, 전처리 시 각 픽셀마다 RGV Value 평균 뺌.
- Very small Receptive Field가지는 Filter인 3x3 사용. 이는 상하좌우, 가운데 개념을 가진 Smallest Size이다
- 1x1 필터 사용. 이유는 이해 못함.
- Spatial Resoluition 유지하기 위해 Padding =1
- Max Pooling = 2x2, stride 2
- FC Layers는 3개
- 처음과 두번째는 4096 Channels, 세번째는 1000 Channels 가진 Softmax Layer
- Activation Function은 ReLU 사용
[2.2 CONFIGURATIONS] (더 번역을 해야 함.)
During training, the input to our ConvNets is a fixed-size 224 × 224 RGB image. The only preprocessing we do is subtracting the mean RGB value, computed on the training set, from each pixel.
. Spatial pooling is carried out by five max-pooling layers, which follow some of the conv. layers (not all the conv. layers are followed by max-pooling). Max-pooling is performed over a 2 × 2 pixel window, with stride 2
(여기서부터 의미가 이해가 잘 안감) A stack of convolutional layers (which has a different depth in different architectures) is followed by three Fully-Connected (FC) layers: the first two have 4096 channels each, the third performs 1000- way ILSVRC classification and thus contains 1000 channels (one for each class). The final layer is the soft-max layer. The configuration of the fully connected layers is the same in all networks. (컨볼루션 레이어 스택(아키텍처마다 깊이가 다름) 뒤에는 3개의 완전 연결(FC) 레이어가 이어집니다. 처음 두 개는 각각 4096개의 채널을 가지고 있고, 세 번째는 1000방향 ILSVRC 분류를 수행하므로 1000개의 채널(각 클래스당 1개씩)을 포함합니다. 마지막 레이어는 소프트 최대 레이어입니다. 완전히 연결된 계층의 구성은 모든 네트워크에서 동일합니다.)
[2.2 CONFIGURATIONS]
The ConvNet configurations, evaluated in this paper, are outlined in Table 1, one per column. In the following we will refer to the nets by their names (A–E). All configurations follow the generic design presented in Sect. 2.1, and differ only in the depth: from 11 weight layers in the network A (8 conv. and 3 FC layers) to 19 weight layers in the network E (16 conv. and 3 FC layers). The width of conv. layers (the number of channels) is rather small, starting from 64 in the first layer and then increasing by a factor of 2 after each max-pooling layer, until it reaches 512.
In Table 2 we report the number of parameters for each configuration. In spite of a large depth, the number of weights in our nets is not greater than the number of weights in a more shallow net with larger conv. layer widths and receptive fields (144M weights in (Sermanet et al., 2014)).
(이 백서에서 평가한 ConvNet 구성은 표 1에 열당 하나씩 요약되어 있습니다. 아래에서는 이름(A-E)으로 네트워크를 지칭합니다. 모든 구성은 2.1절에 제시된 일반적인 설계를 따르며, 네트워크 A의 가중치 레이어는 11개(8개의 변환 레이어와 3개의 FC 레이어)에서 네트워크 E의 가중치 레이어는 19개(16개의 변환 레이어와 3개의 FC 레이어)로 깊이만 다릅니다. 변환 레이어의 폭(채널 수)은 첫 번째 레이어에서 64부터 시작하여 각 최대 풀링 레이어마다 2씩 증가하여 512에 도달할 때까지 다소 작습니다.
표 2에서는 각 구성에 대한 매개변수 수를 보고합니다. 큰 깊이에도 불구하고, 우리 그물의 가중치 수는 더 큰 변환 층 폭과 수용 필드를 가진 더 얕은 그물의 가중치 수보다 크지 않습니다((Sermanet et al., 2014)의 144M 가중치).
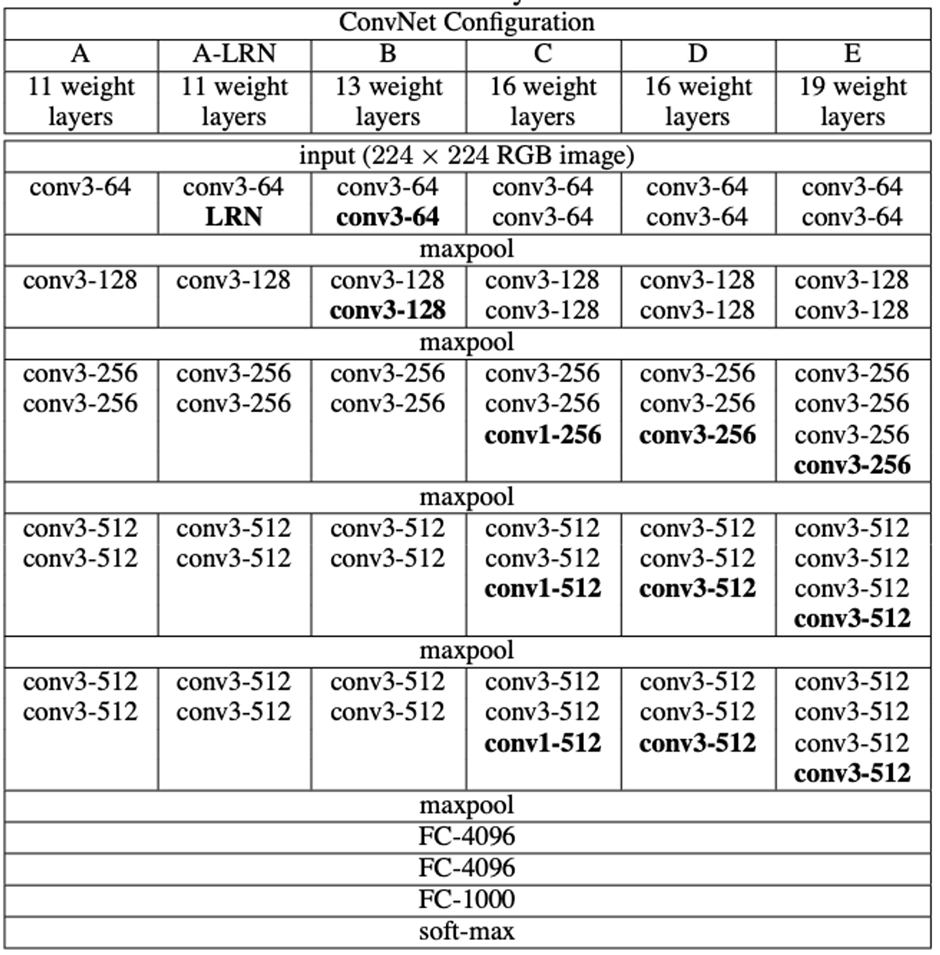
- 처음에 읽을 때 놓친 포인트: Width(Channels)는 64에서 시작해서 512까지 증가
[2.3 DISCUSSION]
이 논문에서 소개하는 모델의 구성은 그 전의 것과 다르다.
1. Rather than using relatively large receptive fields in the first conv. layers (e.g. 11×11 with stride 4 in (Krizhevsky et al., 2012), or 7×7 with stride 2 in (Zeiler & Fergus, 2013; Sermanet et al., 2014)), we use very small 3 × 3 receptive fields throughout the whole net, which are convolved with the input at every pixel (with stride 1)
2. 왜 그렇게 했는지, 장점이 뭔지 설명이 나옴. (이해 못함. 수학 내용이 나옴)
3. 1 by 1 convolution에 대한 설명 (중요한데 놓침). 세 번째 문단
4. 대강 내용을 요약해보자면
| 5주차 수업 PPT 위에 필기해둠 |
[3 CLASSIFICATION FRAMEWORK]
[3.1 TRAINING]
[3.2 TESTING]
[3.3 IMPLEMENTATION DETAILS]
[4 CLASSIFICATION EXPERIMENTS]
[4.1 SINGLE SCALE EVALUATION]
[4.2 MULTI-SCALE EVALUATION]
[4.3 MULTI-CROP EVALUATION]
[4.4 CONVNET FUSION]
[4.5 COMPARISON WITH THE STATE OF THE ART]
[5 CONCLUSION]
It was demonstrated that the representation depth is beneficial for the classification accuracy, and that state-of-the-art performance on the ImageNet challenge dataset can be achieved using a conventional ConvNet architecture (LeCun et al., 1989; Krizhevsky et al., 2012) with substantially increased depth. In the appendix, we also show that
our models generalise well to a wide range of tasks and datasets,
matching or outperforming more complex recognition pipelines built around less deep image representations. Our results yet again confirm the importance of depth in visual representations.
이 연구에서는 대규모 이미지 분류를 위해 매우 심층적인 컨볼루션 네트워크(최대 19개의 가중치 레이어)를 평가했습니다.
표현 깊이가 분류 정확도에 도움이 되며, 깊이가 상당히 증가된 기존의 ConvNet 아키텍처(LeCun 외., 1989; Krizhevsky 외., 2012)를 사용하여 ImageNet 챌린지 데이터 세트에서 최첨단 성능을 달성할 수 있음을 입증했습니다. 또한 부록에서는 딥러닝 모델이 다양한 작업과 데이터 세트에 잘 일반화되어 덜 심도 있는 이미지 표현을 중심으로 구축된 더 복잡한 인식 파이프라인과 일치하거나 그 성능을 능가한다는 것을 보여줍니다. 이러한 결과는 시각적 표현에서 깊이의 중요성을 다시 한 번 확인시켜 줍니다.
'Deep Learning' 카테고리의 다른 글
| [논문리뷰] Seq2Seq (Sequence to Sequence Learningwith Neural Networks) (0) | 2024.05.22 |
|---|---|
| Word2Vec의 Skip-gram 방법 조사 (0) | 2024.05.15 |
| ResNet 논문 리뷰 (0) | 2024.05.13 |
| NLP- CBOW 계산량이 많아 병목현상이 발생한다는 문제점 개선 방법 2가지 (0) | 2024.05.12 |


